하둡 실행 및 동작 확인

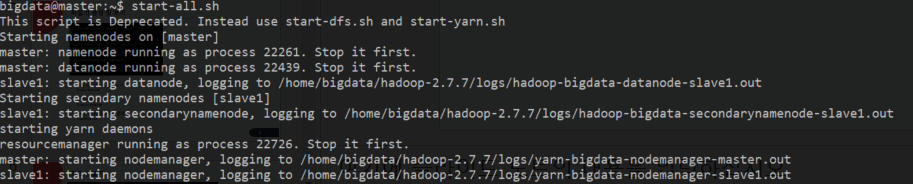
- start-all.sh : 모든 하둡 클러스터의 HDFS 시작, YARN 데몬 실행
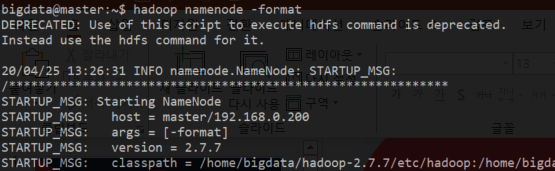
- hadoop namenode -format : 처음 실행 시에 한번만 마스터에서 네임노드를 포맷

- hdfs version : 하둡 버전 확인
- jps : 프로세스 확인
클러스터 동작 확인, 네임노드 웹

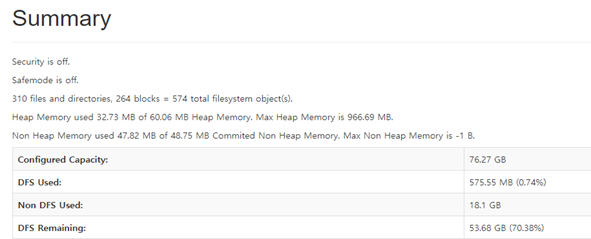
하둡 실행 테스트

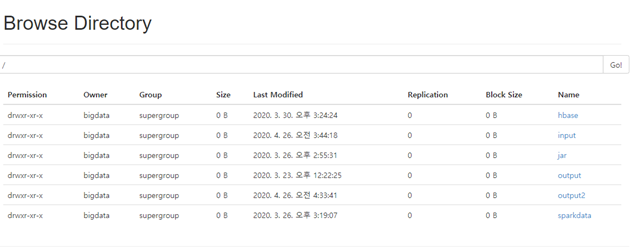
- Root 디렉터리 밑에꺼를 보여준다
- 파일 시스템은 하둡 분산파일 시스템

- input 디렉터리를 만든다

- hadoop fs -put /home/bigdata/hadoop-2.7.7/README.txt /input : 로컬파일시스템의 README.txt을 하둡 파일 시스템 input 디렉터리로 copy

하둡 실행 테스트 - wordcount

- README.txt 파일의 단어 개수들을 세는 프로그램
- 결과는 output이라는 분산파일시스템에 들어가있다.
YARN 자원관리자 확인
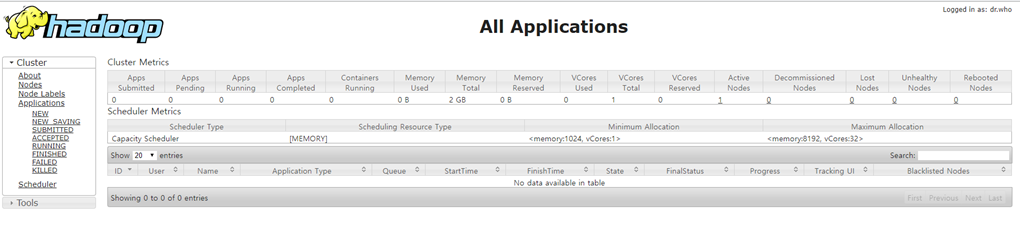
앞의 wordcount 맵리듀스 프로그램을 임의의 데이터에 의해 실행



- NOTICE.txt 파일을 분산파일시스템인 output 폴더에 wordcount 결과값을 저장
앞의 wordcount 맵리듀스 프로그램을 임의의 데이터에 대해 실행
'BigData' 카테고리의 다른 글
| 데이터세트 연산 (0) | 2020.09.24 |
|---|---|
| 데이터세트 생성, 제플린노트북 (0) | 2020.09.24 |
| 아파치 스파크 (0) | 2020.09.24 |
| 하둡에서 datenode가 실행되지 않는경우 (0) | 2020.09.24 |
| 리눅스 명령어, putty, notepad++ (0) | 2020.09.24 |



